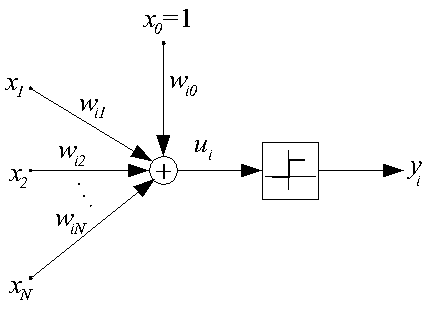
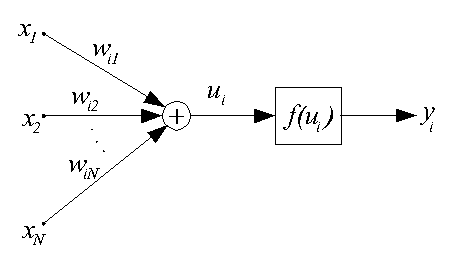
Данная модель искусственного нейрона (ИН) предложена в 1943 г. и называется
также моделью МакКаллока-Пится. В этой модели нейрон считается бинарным
элементом, его структурная схема представлена ниже.
Выходной сигнал нейрона может принимать только два значения {0, 1} по
следующему правилу:
Обучение персептрона требует учителя, т.е. множества {<X1, d1i>, ..., <Xp, dpi>} пар <вектор входных сигналов Xk, ожидаемое значение выходного сигнала dki>. Обучение (отыскание весовых коэффициентов wij) сводится к задаче минимизации целевой функции
К сожалению, для персептрона в силу разрывности функции f(ui) для отыскания минимума E(Wi) применимы методы оптимизации только нулевого порядка.
На практике для обучения персептрона чаще всего используется правило персептрона, представляющее собой следующий простой алгоритм.
Процесс обработки текущей обучающей пары завершается
Следует отметить, что правило персептрона представляет собой частный случай предложенного много позже универсального правила обучения Видроу-Хоффа
Функционирование обученного персептрона в режиме классификации
легко проиллюстрировать графически на примере двухвходового нейрона с
поляризацией, структурная схема которого дана ниже.
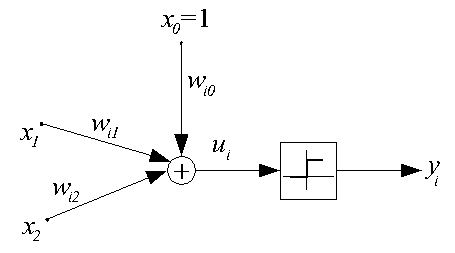
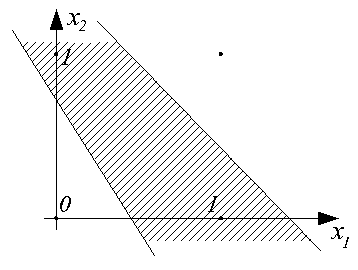
Для такого нейрона ui=wi0+wi1x1+wi2x2. Это выражение определяет плоскость в трехмерном пространстве <x1, x2, ui>, эта плоскость пересекается с плоскостью <x1, x2> по линии, определяемой уравнением
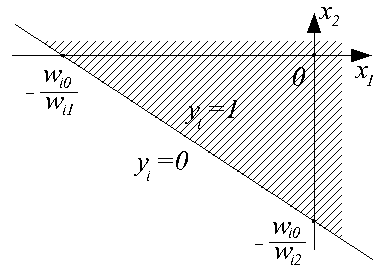
Эта линия разбивает пространство входных сигналов <x1, x2> на две области: в одной из них (заштрихованной) значения ui>0, и, следовательно, функция активации принимает значение 1; в другой - ui<0, и yi=0.
Таким образом, наглядно видно, что персептрон является простейшим линейным классификатором. С его помощью можно обеспечить, например, классификацию, реализующую логические функции И и ИЛИ над входами x1 и x2, как это показано на рисунках.
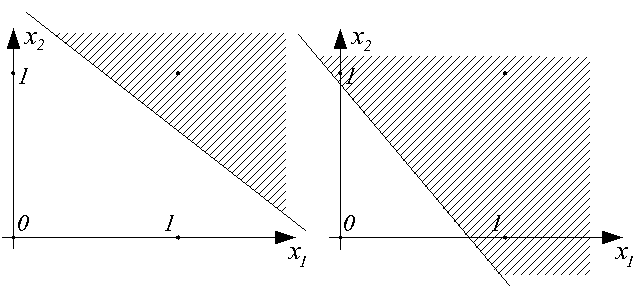
Однако реализовать логическую функцию "исключающее ИЛИ" уже невозможно (см. рисунок ниже).
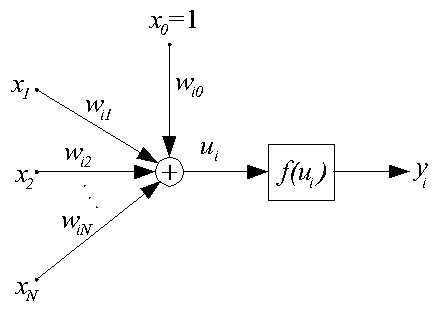
Нейрон данного типа устраняет основной недостаток персептрона - разрывность функции активации f(ui). Структурная схема сигмоидального нейрона представлена ниже.
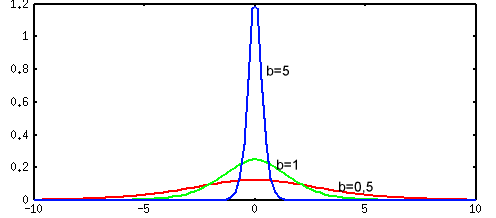
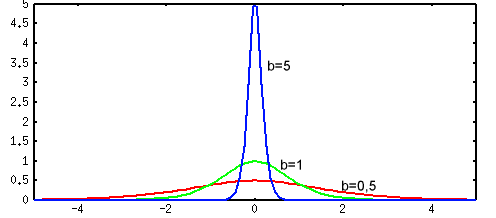
В качестве функции активации f(ui) выступает сигмоидальная функция (т.е. функция, график которой похож на букву S). На практике используются как униполярные, так и биполярные функции активации.
Униполярная функция, как правило, представляется формулой
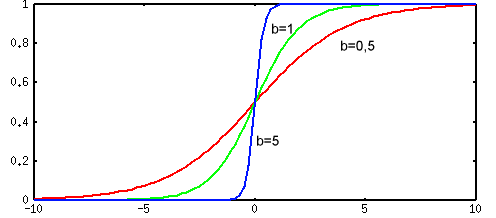
Коэффициент b определяет "крутизну" функций и выбирается пользователем (на практике b для упрощения назначают обычно равным 1).
Производная униполярной функции активации имеет вид
Для обучения сигмоидального нейрона используется стратегия "с учителем", однако, в отличие от персептрона, для поиска минимума целевой функции
J-ая компонента вектора градиента имеет вид
Также возможно обучение сигмоидального нейрона и дискретным способом - сериями циклов уточнения входных весов для каждой эталонной пары <Xk, dki> (см. правило персептрона). При этом коррекция весов после каждого цикла выполняется по следующей формуле:
Необходимо напомнить, что все методы поисковой оптимизации первого порядка - это методы локального поиска, не гарантирующие достижения глобального экстремума. В качестве попытки преодолеть этот недостаток было предложено обучение с моментом, в котором коррекция весов выполняется следующим образом:
Особенностями инстара, отличающими его от нейронов ранее рассмотренных
типов, являются следующие:
Нормализация элементов вектора X производится по следующей формуле:
Обучение инстара с учителем производится дискретно по правилу Гроссберга
На процесс обучения инстара решающее влияние оказывает величина коэффициента обучения nu. При nu=1 веса wij принимают значения соответствующих входов xkj текущей эталонной пары за один цикл обучения (при этом происходит абсолютное "забывание" предыдущих значений wij(t)). При nu<1 в результате обучения коэффициенты wij принимают некоторые "усредненные" значения обучающих векторов Xk, k=1, 2, ..., p.
Предположим, что i-ый инстар был обучен на единственной положительной эталонной паре <X1, 1>. При этом вектор входных весов инстара Wi=[wi1, wi2, ...,wiN]T=X1. В режиме классификации на вход инстара подается вектор X2, тогда на выходе вырабатывается сигнал
Поскольку входные векторы X1 и X2 нормализованы (т.е. |X1|2=|X2|2=1), то выходной сигнал инстара равен просто косинусу угла между векторами X1 и X2.
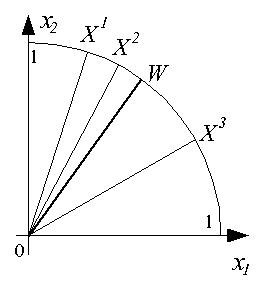
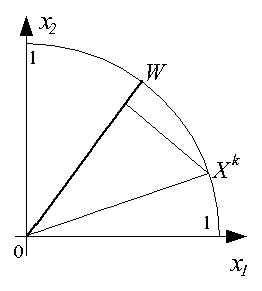
Функционирование инстара наглядно иллюстрируется графически. В режиме обучения
при предъявлении, например, трех положительных примеров, содержащих двухкомпонентные
векторы X1, X2 и X3,
подбирается вектор входных весов W, представляющий собой "усреднение"
этих входных векторов, как это показано ниже.
В режиме классификации при подаче на вход инстара очередного вектора Xk
определяется степень его близости к "типичному" вектору W в виде косинуса угла
между этими векторами, как это показано ниже.
Обучение инстара Гроссберга без учителя предполагает случайный выбор начальных значений входных весов wij и их нормализацию, подобную нормализации вектора входных сигналов X. Дальнейшее уточнение весов реализуется следующей формулой:
Нейроны типа WTA (Winner Takes All - победитель получает все) всегда используются группами,
в которых конкурируют между собой. Структурная схема группы (слоя) нейронов типа WTA
представлена ниже.
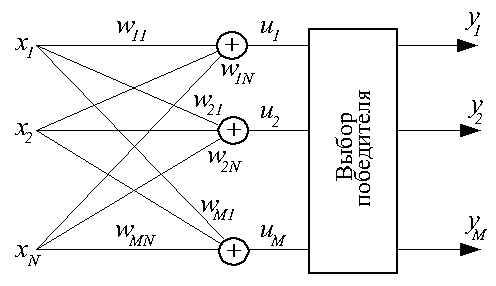
Каждый конкурирующий нейрон в группе получает одни и те же входные сигналы. Каждый нейрон рассчитывает выходной сигнал своего сумматора обычным образом ui=sum[j=1:N](wij*xj). По результатам сравнения всех ui, i=1, 2, ..., M, выбирается нейрон-победитель, обладающий наибольшим значением ui. Выходной сигнал yi нейрона-победителя получает значение 1, выходные сигналы всех остальных нейронов - 0.
Для обучения нейронов типа WTA не требуется учитель, оно практически полностью аналогично
обучению инстара Гроссберга. Начальные значения весовых коэффициентов всех нейронов
выбираются случайным образом с последующей нормализацией относительно 1.
При предъявлении каждого обучающего вектора Xk определяется
нейрон-победитель, что дает ему право уточнить свои весовые коэффициенты по упрощенному
(в силу бинарности yi) правилу Гроссберга
Понятно (см. инстар Гроссберга), что в каждом цикле обучения побеждает тот нейрон, чей текущий вектор входных весов Wi наиболее близок входному вектору Xk. При этом вектор Wi корректируется в сторону вектора Xk. Поэтому в ходе обучения каждая группа близких друг другу входных векторов (кластер) обслуживается отдельным нейроном.
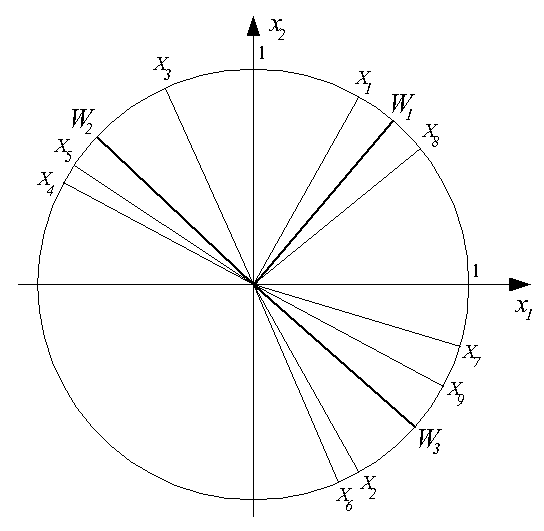
Рисунок ниже иллюстрирует результат обучения слоя нейронов типа WTA на последовательности
девяти двухкомпонентных входных векторов
X1, X2, ..., X9. Здесь
были выделены три кластера входных векторов
{X1, X8},
{X3, X4, X5} и
{X2, X6, X7, X9}.
За их распознавание отвечают три нейрона с векторами входных весов
W1, W2 и W3
соответственно.
Серьезная проблема в использовании нейронов типа WTA - возможность возникновения "мертвых" нейронов, т.е. нейронов, ни разу не победивших в конкурентной борьбе в ходе обучения и поэтому оставшихся в начальном состоянии. Для исключения "ложных" срабатываний в режиме классификации мертвые нейроны после окончания обучения должны быть удалены.
Для уменьшения количества мертвых нейронов (и, следовательно, повышения точности распознавания) используется модифицированное обучение, основанное на учете числа побед нейронов и шрафовании наиболее "зарвавшихся" среди них. Дисквалификация может быть реализована либо назначением порога числа побед, после которого слишком активный нейрон "засыпает" на заданное число циклов обучения, либо искусственным уменьшением величины ui пропорционально числу побед.
Д.Хебб, исследуя поведение природных нервных клеток, зафиксировал (1949г.) усиление связи двух взаимодействующих клеток при их одновременном возбуждении. Это позволило ему предложить правило уточнения входных весов нейрона в следующем виде:
Особенностью правила Хебба является возможность достижения весом wij произвольно большого значения за счет многократного суммирования приращения в циклах обучения. Одним из способов стабилизации процесса обучения по Хеббу служит уменьшение уточняемого веса wij(t) на величину, пропорциональную коэффициенту забывания gamma. При этом правило Хебба принимает вид
К сожалению, при обучении по правилу Хебба нейрона с линейной функцией активации стабилизация не достигается даже при использовании забывания. В 1991г. Е.Ойя предложил модификацию правила Хебба, имеющую следующий вид :
Нейроны данного типа существенно отличаются от ранее рассмотренных. Они используются
только группами, составляя первый слой в многослойных радиальных сетях. Структурная схема
такого нейрона дана ниже.
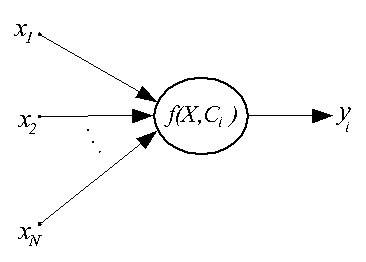
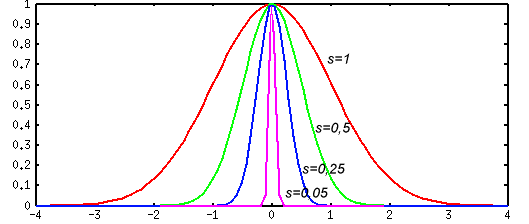
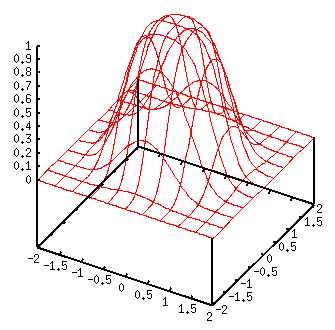
Принципиальное отличие радиального нейрона от сигмоидального (и персептрона) - в том, что сигмоидальный нейрон разбивает многомерное пространство входных сигналов гиперплоскостью, а радиальный - гиперсферой.
Обучение радиального нейрона заключается в подборе параметров радиальной функции Ci и si. Подробно алгоритм обучения радиальных сетей приведен в соответствующем разделе позже. Здесь же в качестве примера приведено выражение, часто используемое для корректировки положения центра нейрона после предъявления k-ого обучающего вектора