Рассматриваемые здесь рекуррентные сети представляют собой развитие однонаправленных персептронных сетей за счет внесения в них обратных связей от выходного или промежуточных слоев на вход. В каждой обратной связи присутствует элемент единичной задержки. За счет этого сеть может рассматриваться как однонаправленная, при этом задержанные сигналы обратной связи просто увеличивают размерность входного вектора. Тем не менее алгоритмы обучения таких сетей более сложны, чем алгоритмы обучения однонаправленных сетей.
Ниже рассматриваются два вида сетей данного типа.
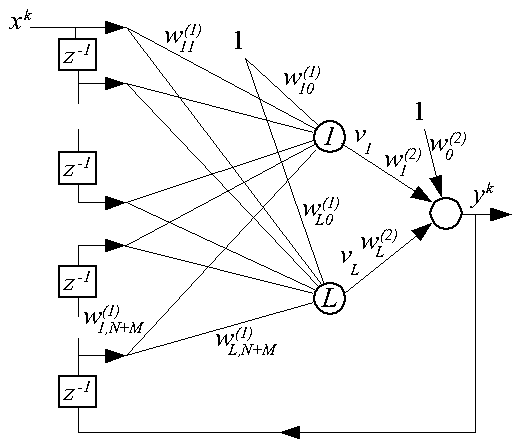
Данные сети получаются из однонаправленного многослойного персептрона MLP введением обратных связей с задержкой с выхода на вход сети, поэтому они получили название RMLP (Recurrent MultiLayer Perceptron). На рисунке дана структурная схема двухуровневой сети с одним входом, одним выходом и L нейронами в первом слое нейронов ("1-L-1").
Входной вектор сети имеет следующий вид:
Пусть все нейроны имеют сигмоидальную функцию активации. Тогда для каждого нейрона первого слоя
а для единственного выходного нейрона
Для обучения сети используется метод градиента, минимизирующий целевую функцию
Найдем компоненты градиента целевой функции сначала для выходного слоя
Ясно, что производная dw(2)i/dw(2)n равна 1 при n=i и равна 0 во всех остальных случаях. Поэтому
Причем
поскольку первые N компонентов входного вектора от весов сети никак не зависят.
В итоге получаем довольно громоздкие рекуррентные выражения для расчета производной выходного сигнала по любому весу выходного нейрона в момент k по ее значениям в M предыдущих моментов k-1, k-2, ...,k-M.
Для расчета производной в первые M моментов от начала обучения полагают
Аналогичным образом получается выражение для производной выходного сигнала yk по весу нейрона входного слоя w(1)nm
После получения выражений для производных алгоритм обучения сети RMLP можно сформулировать следующим образом.
Представленный алгоритм работает в режиме "оффлайн", принимая обучающие пары <xk, dk> и оперативно корректируя значения весов.
Сети RMLP широко используются для построения формальных математических моделей реальных динамических объектов, для чего используется следующая схема обучения.
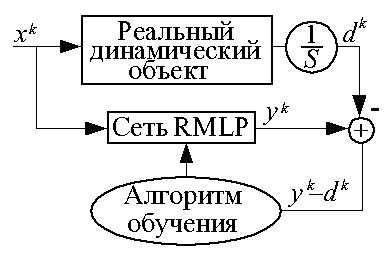
Деление выходного сигнала реального объекта на масштабный коэффициент S необходимо для приведения диапазона изменения этого сигнала к диапазону выходного сигнала сети -1...1 (при использовании биполярной сигмоидальной функции активации).
Обученная по такой схеме сеть RMLP может использоваться, например, в численных экспериментах по отработке алгоритмов управления динамическим объектом.
Сеть данного типа характеризуется частичной рекуррентностью, в ней обратной связью с единичной задержкой охвачен только первый слой нейронов. Структурная схема сети представлена ниже.
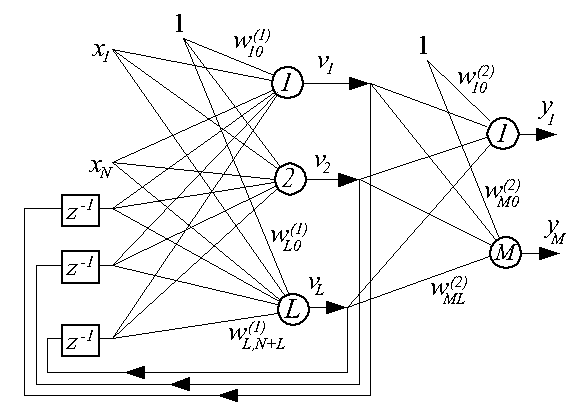
Здесь vl, l=1, 2, ..., L - выходные сигналы первого слоя. Вектор возмущения для момента k имеет следующий вид:
Для нейронов первого слоя
Для нейронов выходного слоя
Целевая функция имеет стандартный вид
Получим выражения для частных производных целевой функции по весовым коэффициентам, необходимые для обучения сети методом градиента. Начнем с выходного слоя.
Поскольку в сети Эльмана обратных связей с выходного слоя нет, то dvkl/dw(2)nm=0 и выражение упрощается.
С учетом того, производная dw(2)il/dw(2)nm равна 1 при n=i и m=l, и равна 0 при всех остальных сочетаниях значений i и l, в итоге имеем
Кстати, легко заметить, что это выражение повторяет формулу расчета производной в методе обратного распространения ошибки для выходного слоя многослойного персептрона. Это так и должно быть, т.к. в сети Эльмана последний слой нейронов обратными связями не охвачен.
Вывод выражений для производных целевой функции по весам нейронов первого слоя более громоздок.
Отдельно определим
Поскольку производная dw(1)lj/dw(1)nm равна 1 при l=n и j=m, а при всех остальных сочетаниях l и j равна 0, то заменим ее дельтой Кронекера delthaln, а произведение delthaln*xkm вынесем из под знака суммирования.
Поскольку во входном векторе сети зависимыми от весов первого слоя нейронов являются только последние L компонент в итоге имеем:
Начальные значения производных для момента k=0 принято выбирать нулевыми.
Алгоритм обучения сети Эльмана можно представить в следующем виде.